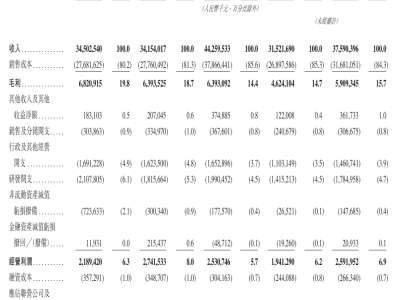
在人工智能視頻生成領域,一項名為Block Cascading的新技術正引發行業震動。這項由國際研究團隊共同開發的技術,通過突破傳統生成框架的束縛,成功將視頻生成速度提升至原有水平的2-3倍,且無需對現有模型進行任何重新訓練。該成果已通過學術論文形式公開,為解決AI視頻生成長期存在的效率瓶頸提供了創新方案。
傳統視頻生成技術采用嚴格的序列化處理模式,如同流水線上的工人必須等待前一個工序完全完成才能開始作業。這種模式雖能保證質量,但效率低下:小型模型每秒僅能生成16幀畫面,大型模型更是低至4.5幀。研究團隊通過逆向思考發現,視頻片段的生成并不需要完全依賴前序片段的最終狀態,半成品信息已足夠支撐后續處理。
核心突破在于"噪聲緩存"機制的建立。研究人員發現,當首個視頻塊完成75%的去噪處理時,即可啟動后續塊的生成流程。這種并行處理模式形成瀑布式工作流:第一個塊處理至50%進度時,第二個塊已推進到75%,第三個塊剛開始去噪。通過共享中間狀態信息,系統在保持連貫性的同時實現了效率飛躍。實驗數據顯示,5個GPU協同工作時,小型模型速度提升至30幀/秒,大型模型達到12.5幀/秒。
技術實現的關鍵在于雙向注意力機制的引入。傳統模型僅允許后續片段參考前序內容,而Block Cascading使同時處理的多個片段能夠相互校準。這種設計不僅維持了視覺質量,在某些測試中甚至產生了更優的生成效果。研究團隊在1.3B參數的Self-Forcing模型、LongLive長視頻模型及14B參數的Krea模型上均驗證了技術的普適性。
交互式應用場景成為最大受益者。傳統系統在用戶修改視頻內容時需重新緩存所有信息,導致200毫秒以上的延遲。新技術通過漸進式內容注入,使場景切換如同數字電視換臺般流暢。用戶研究顯示,觀眾普遍認為Block Cascading生成的交互視頻響應更迅速、過渡更自然,特別在虛擬主播、實時游戲等場景具有顯著優勢。
性能測試數據印證了技術優勢。在標準H100 GPU環境下,30秒視頻的生成時間從傳統方法的67秒縮短至24秒。VBench質量評估顯示,新方法在各項指標上與原始方法持平,部分場景甚至略有提升。靈活的并行配置允許用戶根據硬件條件選擇2-5個塊的并行處理,單GPU環境也能實現約10%的速度提升。
盡管存在GPU擴展效率亞線性增長、預訓練窗口限制等挑戰,但研究團隊強調這些均可通過算法優化逐步解決。特別值得關注的是,該技術完全兼容現有系統架構,視頻生成服務商可快速集成部署。隨著多GPU設備成本下降,這項"即插即用"的加速方案有望推動AI視頻生成進入實時應用新階段。
針對公眾關心的技術普及問題,專家解釋稱,Block Cascading的推廣無需等待模型迭代周期,現有工具用戶將在短期內感受到顯著提升。這種通過優化推理流程實現性能突破的模式,為AI技術應用提供了全新思路,標志著視頻生成技術從追求完美序列向智能并行處理的重要轉型。