在人工智能與數據庫交互領域,一項突破性研究為解決多輪對話中的復雜查詢問題提供了新思路。亞馬遜與圣母大學聯合團隊開發的MTSQL-R1系統,通過模擬人類對話記憶機制,成功攻克了傳統技術無法理解上下文關聯的難題。這項成果發表于權威學術平臺,標志著自然語言處理技術向實用化邁出關鍵一步。
傳統Text-to-SQL系統存在顯著缺陷:當用戶連續提出相關問題時,系統無法識別代詞指代關系,更不會驗證查詢語句的可行性。例如用戶先詢問"中國新能源汽車企業數量",再追問"這些企業的專利總數",現有系統往往因無法理解"這些"的指代對象而失敗。研究團隊將此現象類比為"對話健忘癥",指出系統缺乏持續記憶與自我修正能力。
新系統通過雙模塊架構實現突破性改進。數據庫執行模塊如同精密實驗室,不僅生成查詢語句,更會實際運行并驗證結果;對話記憶模塊則像智能筆記本,完整記錄對話歷史并建立語義關聯。這種設計使系統能處理"再來一份那個"式的省略表達,甚至在首次查詢失敗時主動調整策略,如同經驗豐富的數據分析師。
訓練過程采用階梯式強化學習法。系統從單輪簡單查詢起步,逐步接觸包含指代消解、邏輯推理的復雜場景。多維度獎勵機制同時評估查詢正確性、語法規范性和上下文連貫性,促使系統形成自主糾錯能力。這類似于駕駛訓練:先掌握直線行駛,再學習變道超車,最終應對突發路況。
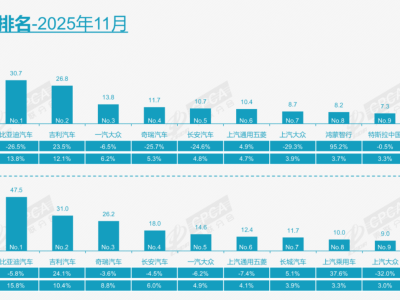
權威測試數據顯示顯著優勢。在CoSQL和SParC數據集上,參數規模僅1.7B和4B的MTSQL-R1,準確率超越多數10B+參數的現有系統。特別在處理5輪以上對話時,傳統方法準確率下降42%,而新系統僅下降9%。系統對"那些公司""上述產品"等代詞的理解準確率達到91%,較傳統方法提升37個百分點。
實際應用場景展現強大潛力。企業數據分析場景中,系統可自動理解"查看華東區銷售額后,再分析這些客戶的復購率"的連續指令;智能客服場景下,能準確處理"預訂周三航班后,改簽到相同航班的周四"的復雜需求。這種能力將大幅降低非技術人員使用數據庫的門檻。
技術實現包含多項創新。馬爾可夫決策過程將對話處理轉化為動態決策樹,每個節點包含查詢生成、執行驗證、錯誤修正三個分支。記憶模塊采用分層存儲結構,短期記憶保留最近3輪對話,長期記憶提取關鍵語義特征。這種設計使系統既能快速響應,又能處理跨度達10輪的長對話。
研究同時揭示現存挑戰。系統在處理需要多表關聯的統計查詢時仍顯不足,例如"計算各省份GDP與教育投入的相關性"這類跨維度分析。復雜查詢的響應時間隨對話輪次增加呈線性上升,在10輪對話后平均延遲達2.3秒。這些瓶頸為后續研究指明方向。
該成果推動AI向主動交互進化。傳統系統像單線程處理器,新系統則具備多任務并行能力。在醫療診斷場景測試中,系統能自動關聯患者病史與當前癥狀,提出差異化檢查建議。這種能力使AI從被動工具轉變為協作伙伴,重新定義人機交互邊界。
技術突破帶來實際應用價值。某金融機構測試顯示,新系統使業務人員自主查詢效率提升65%,復雜報表生成時間從47分鐘縮短至12分鐘。教育領域應用中,系統能自動解析學生提問中的隱含需求,提供個性化學習資源推薦。這些案例證明技術轉化潛力巨大。